
Webサイトを作成していると、検索エンジンのクローラーに訪問して欲しくないページ(例:プライベートなページなど)を作成する場合があるかもしれません。そんな時は、robots.txt というファイルを作成し、インデックスに登録するページを制御することができます。但し、絶対というわけではありませんが…
今回は、robots.txt で基本的によく使う記述をまとめてみます。
robots.txt ファイルの作成
robots.txt ファイルは通常のテキストファイルになりますので、普通のテキストエディタ(メモ帳など)で作成できます。ファイル名は間違いなく robots.txt としてください。作成した robots.txt ファイルはWebサイトのルート直下にアップロードします。当サイトで設置した場合のアドレスは以下の通りになります。
基本的な記述について
User-Agentでクロールの指示
User-Agent: はどのクローラーにクロールを指示するかの指定になります。通常は「*」を指定して、全てのクローラーを許可するようになるかと思います。User-Agent:Googlebotなどと指定すれば、Googlebotのみ許可もできますが、あまり使用することは無いでしょう。
通常は下記の様に記述して問題ないかと思います。
Disallowでアクセス制御
Disallowはアクセスを制御するディレクトリまたは、ファイルを指定する記述です。いくつか記述方法がありますので、例を記載します。
サイト全体をブロックする場合
特定のディレクトリとその中のページやファイル全てをブロックする場合
上記はhoge-directoryのディレクトリ内をブロックしています。
特定種類のファイルをブロックする場合
上記の場合、拡張子が.pngのファイルをブロックしています。
Allowでクロール制御下のディレクトリ内の特定ファイルのみ許可
Disallowでクロール制御をしているディレクトリ内に、このページだけはクロールして欲しいというページなどがあればこのAllowを指定します。注意事項としましては、Disallowを記述した行よりも下の行に記述します。
XMLサイトマップの指定
XMLサイトマップ(検索エンジン用サイトマップ)のアドレスを記載することによって、クローラーにXMLサイトマップの存在を知らせることができます。
sitemap_index.xmlの部分は、XMLサイトマップのファイル名に合わせて変更してください。sitemap.xmlとなっている場合はsitemap.xmlを指定してください。
robots.txtのテスト
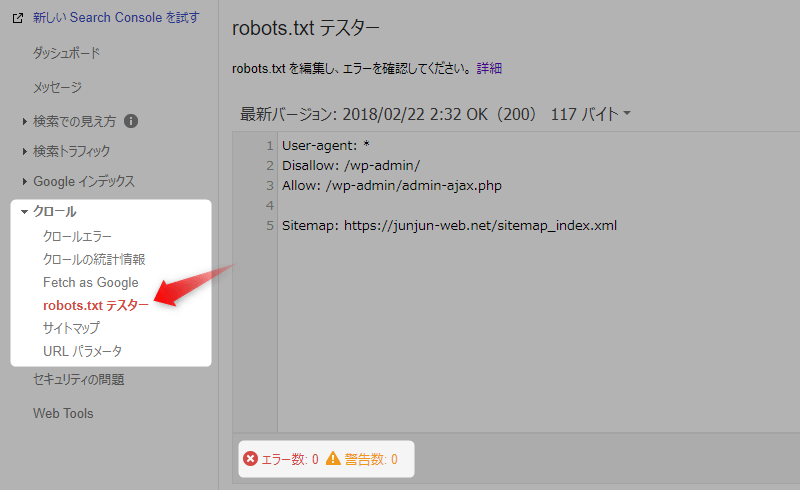
Webサイトを Search Console に登録している場合、robots.txtテスターで問題なく設置出来ているかの確認ができます。Search Console にアクセスして、[クロール] → [robots.txtテスター]を開いてください。robots.txtに記載した内容が表示され、エラー数と警告数が0であれば問題ありません。
まとめ
robots.txt の設置は必須ではありませんが、Googleクローラーにクロールして欲しくないページがある場合は指定した方が、良いかもしれません。(Googlebot以外は言うこと聞かないかもしれませんが…)また、XMLサイトマップを指定しておけば、Google検索エンジンのクローラーがサイトを訪問した時に、サイトの構造を効率よく知らせることができるので、自分は必ず指定しています。
以上、robots.txt の基本的な記述方法でした。